
Behind the fast-moving waves of modern Artificial Intelligence, the most valuable lesson often comes from building something small, focused, and deeply practical. For a developer, shifting from consumer to creator means understanding how data flows, how models reason, and how we can ground wild AI imaginations into absolute truth.
This journey led to the birth of the Biology RAG Assistant—a lightweight project designed to explore Retrieval-Augmented Generation (RAG) while solving a real-world educational need.
The Core Concept: Education Meets Strict Logic
In education, accuracy isn't just a preference; it's a mandatory requirement. Traditional AI models are notorious for "hallucinating"—generating highly confident but entirely fabricated answers. If a student asks a biology question, the AI must not invent facts.
To solve this, the Biology RAG Assistant acts as a digital librarian, built entirely on top of 12 Natural Science textbooks (Grades 6 to 9) from Vietnam's current official curriculum:
- Cánh Diều (CD)
- Chân Trời Sáng Tạo (CTST)
- Kết Nối Tri Thức (KNTT)
Instead of letting the model answer from its generic pre-trained knowledge, the system forces the AI to look only inside these 12 books.
Key Features of the System
This assistant was architected with a strict constraint: restricting answers outside the source material to the absolute minimum. Here is how it assists teachers and students:
- Fact-Grounded Text Responses: When an inquiry is submitted, the assistant scans the textbook database to synthesize a clear, concise answer. No fabrications allowed.
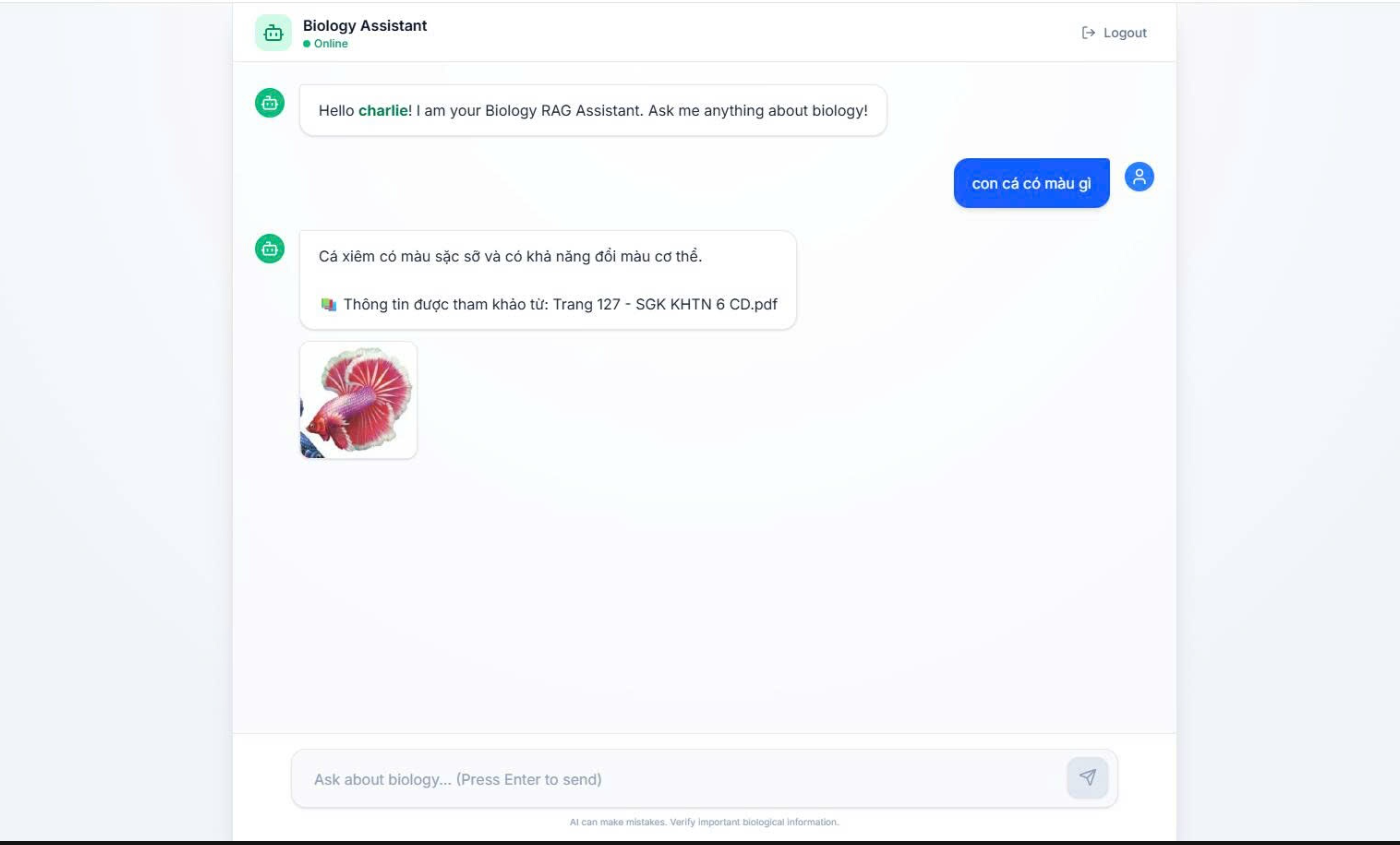
- Transparent Citations: Trust requires verification. Every answer is served alongside its exact source, detailing the specific book and page number (e.g., Page 127 - SGK KHTN 6 CD.pdf). This allows educators and students to double-check information instantly in their physical books.
- Visual Evidence: Biology is inherently visual. The assistant automatically retrieves and displays corresponding diagrams, graphs, or photographs directly from the textbook source if they match the context of the question.
- Clear Boundaries: If a user searches for a concept completely missing from the 12 textbooks, the application will not guess. It straightforwardly notifies the user that the requested content cannot be found within the provided documents.
From Interface to Implementation
The design focuses on a clean, distraction-free interface. It starts with a minimalist portal prompting the user for their name before granting access to the knowledge base. Once inside, the experience mirrors a direct chat with a scientific repository, complete with real-time status indicators ("Thinking...") while the vector database handles the context retrieval.

For example, when a user queries "what color is the fish?" (con cá có màu gì), the system doesn't talk about general marine biology. It isolates the exact text talking about the Siamese fighting fish (Cá xiêm) from page 127 of the Cánh Diều Grade 6 textbook, delivers the text, cites the document cleanly, and renders the corresponding illustration from the book pages.
Open Source and Exploration
This project is a modest first step toward understanding how AI can be safely integrated into local, domain-specific fields like classroom learning. It serves as a playground for tuning embeddings, perfecting chunking strategies, and managing document-based context windows.
The entire codebase is open and ready for exploration. You can view the repository, check out the architecture, or spin up your own version here:
👉 Source Code Repository: https://github.com/lcdkhoa/project-bio-rag 🚀 Live Application: https://bio-rag.lcdkhoa.com/
Let's keep learning, line by line, page by page.